
Didattica 2021-2022
Il Master Big Data è un master full-time erogato interamente online che avrà durata di un anno a partire da Novembre. L'attività didattica prevede due fasi principali: la prima fase, che copre il periodo da Novembre a fine Luglio, è dedicata alle lezioni frontali e attività progettuali; mentre la seconda fase, che copre il periodo Agosto-Dicembre, è dedicata al tirocinio di 475 ore che gli studenti svolgeranno presso i nostri partners.
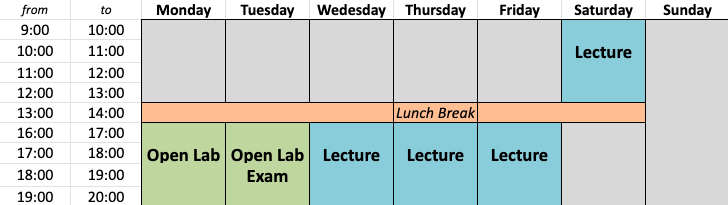
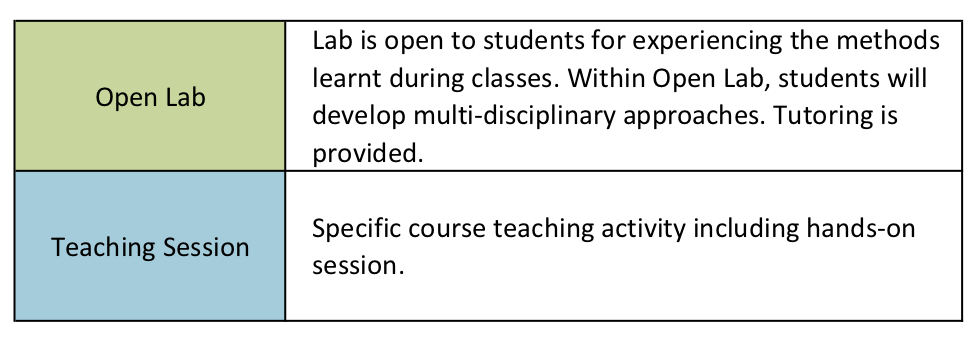
L'attività didattica settimanale durante la prima fase prevede alcune ore di lezioni frontali concentrate dal mercoledì al sabato e delle ore di laboratorio (non obbligatorie) durante le quali gli studenti potranno esercitarsi sperimentando sul campo i metodi presentati a lezione con il supporto di tutor. Il consiglio del Master ha stabilito che ai fini del conseguimento del titolo sarà necessaria la presenza obbligatoria dello studente ad almeno il 70% delle ore di lezioni frontali. L'organizzazione didattica settimanale è descritta in dettaglio nelle seguenti immagini:
Crediti Formativi Universitari (CFU)
Il Credito Formativo Universitario (CFU) è l'unità di misura del volume di lavoro di apprendimento, richiesto ad un allievo in possesso di adeguata preparazione iniziale, per l'acquisizione di conoscenze ed abilità richieste da una certa attività formativa. Esso corrisponde a 25 ore di lavoro complessivo, che comprende sia le ore di didattica frontale, sia lo studio individuale, sia altri tipi di attività (come il tirocinio). Ogni attività formativa ha associato un certo numero di crediti, che vengono acquisiti con il superamento di una verifica del profitto, e non sostituiscono il voto.
L'attività didattica sarà supportata dall'uso della piattaforma Moodle, dove gli studenti troveranno tutto il materiale didattico.
![]()
Insegnamenti 2021-2022
Gli insegnamenti previsti, con i rispettivi obiettivi formativi, sono elencati di seguito.
Questo modulo introduce nozioni della teria dei grafi per analizzare grandi reti socio-economiche. L'analisi poi ci condurrà alla descrizione della modellazione di vari fenomeni e alla corretta definizione di benchmarks con l'uso di un approaccio ispirato alla fisica statistica classica.
Il modulo ha l'obiettivo di allineare le competenze informatiche ed analitiche di base degli studenti, in particolare in materia di basi di dati, di analisi statistica ed esplorativa dei dati e di linguaggi di programmazione.
Il modulo si propone di introdurre le nozioni etico-legali di privacy, anonimato, trasparenza e non-discriminazione, anche in riferimento al quadro normativo comunitario e alla sua evoluzione in corso. Saranno mostrati i modelli e le tecnologie di privacy-by-design, di auditing dei modelli predittivi e di difesa dei diritti personali, che permettono l'analisi di Big Data nel rispetto del diritto alla protezione dei dati personali, alla trasparenza e al trattamento non discriminatorio.
Il modulo prevede attività seminariali che riportano esperienze e casi di studio/uso di Big Data analytics e Social Mining da parte del laboratorio SoBigData.eu e delle aziende ed istituzioni partner del Master.
Il modulo presenta le tecniche di acquisizione di big data dalle principali sorgenti ad oggi disponibili, incluso dati telefonici, dati di navigazione satellitare, dati di acquisto e di consumo e dati da social media e social networks, open data e dati amministrativi, dati da sensori personali e ambientali. Vengono anche discusse le modalità partecipative di raccolta dei dati attraverso sistemi di crowdsourcing and crowdsensing come i giochi con scopo e le campagne virali.
Il modulo mira innanzitutto a presentare le caratteristiche principali dei processi di innovazione nelle imprese e nelle istituzioni. Oltre ad alcuni cenni teorici di economia dell’innovazione, enfasi verrà posta sulla gestione dei processi innovativi (ruolo della R&S, dell’Open Innovation, ecc.). Verranno poi descritte le nuove opportunità di innovazione rese possibili dagli avanzamenti recenti nei processi di raccolta ed elaborazione di dati su vasta scala. Infine, dopo avere spiegato i concetti e i modelli di business model e di start-up, verrà svolto un eservizio di business model innovation teso ad esplorare le potenzialità dei Big Data nell’aprire nuove possibilità di business.
Il modulo presenta tecnologie e sistemi per la progettazione, il popolamento e l'interrogazione di Data Warehouse per il supporto alle decisioni. L’accento viene posto sulle tecnologie e sull’analisi di problemi applicativi utilizzando esempi e casi studio, con esercitazioni in laboratorio. Lo studente acquisirà conoscenze e capacità sulle principali tecnologie per la Business Intelligence come
ETL (Extract, Transform and Load), Data Warehousing, Analytics SQL, OLAP (Online Analytical Processing).
Il modulo si propone di fornire un’introduzione ai concetti di base del data mining e del processo di estrazione della conoscenza, con approfondimenti sui modelli analitici e gli algoritmi più diffusi per il clustering, la classificazione e la scoperta di patterns, anche in riferimento alle nuove sorgenti di Big Data.
Il modulo ha l'obbiettivo di preparare gli studenti per la creazione di presentazioni appropriate dei dati e della conoscenza estratta attraverso strumenti e narrative multimediali.
Il modulo prima presenta le tecniche di visualizzazione per una presentazione efficace delle informazioni che derivano da sorgenti dati differenti: dati strutturati (relazionali, gerarchie e alberi), dati relazionali (social network), dati temporali, dati spaziali e dati spazio-temporali.
Infine, il modulo presenta esperienze significative di giornalismo e storytelling basate su informazione quantitativa estratta da diverse sorgenti.
Il corso introduce i fondamenti dell'artificial neural network e fornisce una panoramica delle principali tecninche e dei modelli di deep learning. In particolare sono mostrati in dettaglio i modelli neurali che sono utili per affrontare task predittivi su dati vettoriali, sequenziali e immagini e utili per il deep learning generativo, inclusi variational e adversarial learning.
L'informazione che circola sul web e sui social networks e' sempre piu' di natura multimediale. La possibilita' di capire il contenuto e di cercare documenti multimediali su larga scala, specialmente in assenza di descrizioni testuali, e' diventata uno strumento strategico. Il modulo ha l'obbiettivo di presentare strumenti per analizzare ed estrarre informazione da dati multimediali, per cercarli in enormi database.
Il corso propone l’insegnamento di concetti base del paradigma di calcolo distribuito tramite MapReduce dal punto di vista teorico e pratico, in particolare ci si focalizzerà su Hadoop per lo sviluppo di competenze nell'uso di strumenti di calcolo ad alte prestazioni per il data engineering, l'analisi di dati e l'utilizzo di tecniche di data mining. Gli studenti impareranno come i classici algoritmi di data mining possono essere applicati sui Big Data usando Hadoop (Spark). Set di dati reali (e open source) verranno utilizzati per presentare esempi e per consentire agli studenti di costruire i propri progetti.
Il modulo prevede la descrizione della struttura di un motore di ricerca e di strumenti di Text Mining, analizzando le loro caratteristiche e limiti dal punto di vista computazionale, dei parametri precision/recall/F1, e di espressività delle interrogazioni supportate. Il modulo prevede anche una parte hands-on in cui si descriveranno e utilizzeranno alcuni ben noti strumenti open-source Python per il crawling e analisi di pagine web, l’annotazione semantica di testi (TagMe), e l’indicizzazione di collezioni documentali (ElasticSearch).
Il modulo ha lo scopo di fornire agli studenti gli strumenti e le conoscenze necessarie ad analizzare dati su larga scala provenienti da Online Social Networks. Nel modulo vengono presentati gli strumenti di analisi necessari, vengono poi illustrati i risultati ottenuti applicando tali strumenti a vari tipi di reti sociali. Tali strumenti vengono applicati ai due modi principali di rappresentare una OSN tramite grafi, considerando cioè il social e l’interaction graph.
Nel corso delle ore di laboratorio, gli studenti applicano i concetti appresi a lezione su dataset reali di Online Social Networks. Vengono svolti laboratori sull'analisi dei vari tipi di grafo sociale visto a lezione. Gli studenti apprendono così l'utilizzo di strumenti software di riferimento per l'analisi di dati provenienti da Online Social Networks.
Questo modulo presenta metodologie, tecniche e tools di analisi statistica per data science: conoscenza di base della teoria della probabilità, variabili random, modelli statistici, estimation theory, test delle ipotesi, bootstrap, e conoscenza di base dell'analisi delle serie temporali. Il modulo mostra l'applicabilità in casi di studio nel dominio della finanza.
Questo modulo introduce le principali tecniche per l'analisi e il mining delle opinioni degli utenti generate principalmente nel web.
Il corso si focalizza principalmente su metodi di text mining applicati al testo generato nei social media e su tecniche di web mining. Usando dei query log di un motore di ricerca reale come caso di studio, gli studenti saranno guidati nello sviluppo di un insieme di metodologie per l'analisi di dati che ha lo scopo di creare la base di conoscenza necessaria a costruire un sistema di raccomandazione.
Il corso inoltre discute come la stessa informazione può essere usata per ottimizzare il ranking nei Web services. A tal fine, il modulo introduce tecniche di "learning to rank" che hanno lo scopo di stimare la rilevanza degli oggetti rispetto ai requisiti dell'utente. La presentazione delle nozioni introdotte sarà supportata da diversi casi di studio sviluppati nel laboratorio SoBigData.eu.
Il corso ha lo scopo di introdurre le principali tecniche di data mining e machine learning (incluso deep learning) per l'analisi di dati temporali, in particolare di time series e dati spazio-temporali relativi alla mobilita' umana. La presentazione delle nozioni sara' supportata da diversi casi di studio sviluppati dal laboratorio SoBigData.eu.
Il periodo di tirocinio previsto dal Master è di 500 ore, corrispondenti a 20 CFU, da svolgersi individualmente o in piccoli gruppi presso una delle aziende ed istituzioni partner del master, sulla base di un progetto concordato e sotto la supervisione di un team di tutor composto da docenti del master e responsabili aziendali.
Al termine del periodo di tirocinio, il candidato redige una tesina per descrivere il lavoro svolto, le metodologie utilizzate e i risultati dell'attività di tirocinio svolta presso l'azienda o l'istituzione ospitante. La tesi viene presentata dal candidato in sede di esame finale del master. La tesina viene valutata in base alla qualità del materiale presentato e alle capacità di analisi e di sintesi dimostrate dal candidato nella stesura della tesina stessa.
Periodo Tirocino: Settembre - Dicembre.