
Teaching 2021-2022
The Big Data Master is a full-time master delivered entirely online that starts in January and lasts one year. The teaching activity has two main phases: the first phase, that covers the period from November to end July, is dedicated to lectures and project activities; the second phase, that covers the period from August to December, is dedicated to a 475 hours Internship by the Partners.
The weekly teaching activity during the first phase is divided in lectures (wednesday to saturday) and lab hours (not mandatory) that allow student to experiment on the field the methods shown in the lectures with the support of the tutors. The steering committee has decided that at least 70% attendance of the lectures hours is required. The weekly teaching activity is described in the following images:
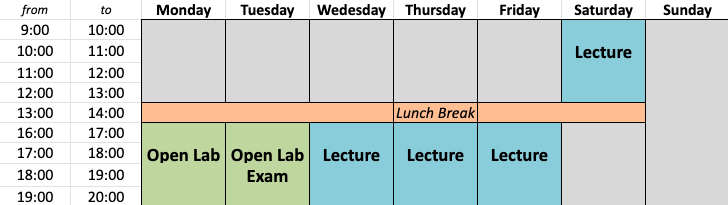
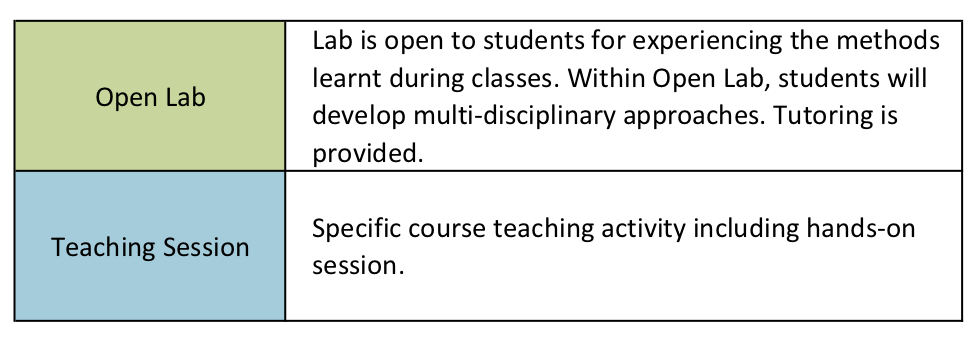
European Credit Transfer System (ECTS)
The European Credit Transfer System (ECTS) is the unit of measure of the volume of learning work, required to a student having an adeguated initial know-how, for acquiring the knowledge and abilities required by a teaching activity. It is equivalent to 25 hour of work, including lectures, individual studies and other types of activities (like internship). Each teaching activity has an associated number of credits, that are assigned after an exam.
The teaching activity is supported by the Moodle platform, where students will find all the teaching material.
![]()
Teaching 2021-2022
The scheduled courses and their educational objectives are listed below.
In this course we start from the basic notions of graph theory and self-similar phenomena in order to correctly analyse large socio-economic networks. From this analysis we then proceed in the description of the modelling for various classes of phenomena and to the correct definition of benchmarks through an approach inspired by classical statistical physics.
The objective of the module is to align the competences of the students in computer science and base, in particular about databases, structured data analysis, statistics and programming languages.
The module aims to introduce ethical and legal notions of privacy, anonymity, transparency and non-discrimination, also referring the Directives and Regulations of the European Union and their ongoing evolution. The module will show technologies for Privacy-by-Design, for predictive model auditing and for protecting the users' rights and that allow the analysis of Big Data without harming the right to the protection of personal data, to transparency and to a fair treatment.
The module si composed by several Seminars on experiences and case- and use-studies of Big Data analytics and Social Mining from the SoBigData.eu labs and from the companies and institutions that are partners in the Master.
This module presentes techniques and methods for acquisition of Big Data from a large sources of data available, including mobile phone data, GPS data, customer purchase data, social network data, open and administrative data, environmental and personal sensor data. We discuss also several participatory methods for crowdsourcing or crowdsensing collection of data through ad hoc campains like serious games and viral diffusion.
The module aims to show the main characteristics of the innovation processes in companies and institutions. After some basics of innovation economics, the management of the innovation processes will be presented (role of R&D, Open Innovation, etc.). The module also shows new innovation opportunities available after the last progresses in large scale data acquisition and elaboration, the basics of business models and start-ups. An exercise of business model innovation will try to explore che big data potential in opening new business opportunities.
The module presents technologies and systems for designing, populating and querying Data Warehouse for decision support. The emphasis is on technologies and analysis of application problems by using examples and case studies. The student will acquire knowledge and skills on major technologies for Business Intelligence such as ETL (Extract, Transform and Load), Data Warehousing, Analytics SQL, OLAP (Online Analytical Processing).
The module provides an introduction to base concepts of data mining and knowledge extraction process, introducing analytical models and algorithms for clustering, classification and pattern discovery, also referring Big Data sources.
The module aims at preparing students to the approprieted presentation of data and knowledge extracted from them through visualization tools and narratives that exploit multimedia.
The module first presents the basic visualization techniques for the effective presentation of information from several different sources: structured data (relational, hierarchies, trees), relational data (social networks), temporal data, spatial data and spatio-temporal data.
Then, it also presents the most significant recent experiences in journalism and storytelling based on quantitative information extracted from various data sources.
The course will first introduce the fundamentals of artificial neural networks and, then, it will provide an overview of the main techniques and models of the deep learning field. Specific focus will be placed on detailing neural models that are useful for addressing predictive tasks on vectorial, sequential and image data, and to generative deep learning, including variational and adversarial learning.
The information circulating on the web and social networks is increasingly multimedia in nature. The possibility to understand the content and to search for multimedia documents on a large scale, expecially in the absence of textual descriptions, has become a strategic tool. The module aims to present tools for analyzing and extracting information from multimedia data, in order to search them in huge databases. This module is based on hands-on work.
This course aims at teaching the basic theoretical concepts behind the MapReduce distributed computing paradigm, and Hadoop in particular, and at building expertise in the practical usage of high-performance computing tools for data engineering, analysis and mining. In particular, the students will learn how classical data mining algorithms can be applied to Big Data using Hadoop (Spark). Real (and open source) datasets will be used to present examples and to let the students build their own projects.
The module provides the description of a search engine structure and of Text Mining tools, by analyzing their characteristics and limits with respect to the computational cost, the precision/recall/F1 parameters, and the expressivity of the supported queries. The module is also based on hands-on activities that will present well-known open-source Python tools for the crawling and analysis of web pages, the semantic annotation of texts (TagMe), and the indexing of text data collections (ElasticSearch).
The internship period is 500 hours, 20 CFU, that single student or a small group of students have to spend in one of the companies and institutions partner of the master, working on an agreed project and under the supervision of a team of tutors composed by the teachers of the master and the management companies.
At the end of the internship, the student has to write a thesis describing the work done, the methodologies used and the results of the internship activity. The thesis will be presented by the student in the final exam of the master. The evaluation of the thesis will be based on the quality of the document, on the analysis and synthesis capabilities shown by the student during the presentation.
Periodo Tirocino: September - December.
This course introduces students to the theories, concepts and measures of Social Network Analysis (SNA), that is aimed at characterizing the structure of large-scale Online Social Networks (OSNs). The course presents both classroom teaching to introduce theoretical concepts, and hands-on computer work to apply the theory on real large-scale datasets obtained from OSNs like Facebook and Twitter. The course aims to discuss in particular how the structural properties of social networks can be analyzed through SNA techniques, and how these properties can be used to characterize social phenomena arising in the society.
This module introduces the main methods of analysis and mining of opinions and personal evaluations for users based on Big Data generated on the web or other sources. Emphasis will be put on text mining method applied to text originated on social media. Lessons will be supported by case studies developed in the SoBigData.eu lab.
This module introduces the main techniques for the analysis and mining of user based opinions on Big Data generated mainly from the web. Emphasis will be put on text mining methods applied to text originated on social media. Moreover, the module presents the main web data analysis techniques. By using the query log of a real search engine as a case study, students are guided in the development of a set of methodologies for data analysis aimed at creating the knowledge base for building a recommendation system. Then, the course discusses how the same information can be used to optimize the ranking in Web services. To this regard, the course introduces the learning to rank techniques aimed at estimating the relevance of objects with respect to specific user information needs.
The presentation will be supported by several case studies developed with the SoBigData.eu Laboratory.
The purpose of the course is to introduce the main techniques in data mining and machine learning (including deep learning approaches) for the analysis of temporal data, in particular for time series and spatio-temporal data related to human mobility. The presentation will be supported by several case studies developed with the SoBigData.eu Laboratory.