
Pier Paolo Pasolini nel 1963 girò l’Italia assieme al produttore Alfredo Bini alla ricerca di luoghi e volti per il film “Il Vangelo secondo Matteo”. In questo viaggio per l’Italia tuttavia Pasolini ha un desiderio ricorrente: scoprire l’opinione degli italiani riguardo sessualità, tematiche di genere e buon costume. Dunque, ispirato dai nuovi esperimenti di cinema verità dell’epoca, imbraccia la cinepresa e con un piccolo microfono alla mano intervista un vasto numero di italiani di diversa età, estrazione sociale e genere, nelle piazze, spiagge, e salottini borghesi del Belpaese. La peculiarità e l’attenzione per i contesti scelti da Pasolini portarono alla luce un film-inchiesta atipico, in cui il linguaggio – e spesso la reticenza– degli italiani fecero da protagonisti.
Come potremmo tuttavia contestualizzare la ricerca di Pasolini sul linguaggio sessuale oggi? A più di 50 anni da Comizi d’Amore, la discussione su tali tematiche è mutata radicalmente, sia nel contenuto che nella forma. Ma ciò che è indubbiamente cambiato sono anche i luoghi ed i media dove tali conversazioni avvengono e attraverso i quali si disperdono. I luoghi della discussione contemporanea, “agorà” ibride tra piazze materiali e celle sensorizzate, fanno sì che le conversazioni che avvengono al loro interno lascino delle tracce digitali, impresse su memoria rigida o su cloud. Ambizione e stimolo di ricerca hanno portato dunque ad unire l’intuizione di Pasolini a moderne tecniche di estrazione ed analisi dati, per poter quantificare, modellare e –forse– comprendere meglio il linguaggio sessuale e di genere in Italia oggi.
Le metodologie adottate in questa ricerca hanno cercato di tradurre approcci giornalistico-documentativi scelti da Pasolini, in metodologie analitiche basate sulla raccolta di dati e l’analisi e la classificazione dei medesimi. Di seguito sono elencate gli obiettivi e le analisi corrispondenti a singole task di ricerca informativa che concorrono a strutturare e a definire lo studio nel totale.
I temi e le instanze della discussione sessuale in Italia sono molto cambiati dagli anni ‘60, specialmente sul fronte dei diritti civili: Pasolini al tempo cercava di comprendere i pareri riguardo la Legge Merlin sull’abolizione delle “case chiuse” e sulla legislazione del divorzio. Oggi – nel 2021– il dibattito sessuale è imperniato principalemente attorno al tema dell’omotransfobia e della discriminazione di genere. Per comprendere i confini del fenomeno ci siamo fatti affiancare da un esperto del dominio, l’attivista e presidente di Certi Diritti LGBTQI+ Yuri Guaiana. Parlando dei dati sulla discriminazione in Italia, Guaiana ha rimarcato l’importanza di tali dati per lo Stato e le Amministrazioni per poter definire politiche pubbliche mirate, ma anche per gli attivisti, per poter operare in modo più preciso. Tuttavia alla nostra domanda sulla quantità di dati a nostra disposizione oggi, Guaiana ha risposto con un eufemismo molto eloquente “i dati sul fenomeno in Italia purtroppo mancano, tuttavia sempre più persone parlano di questo tema”.
In fase iniziale del progetto abbiamo cercato di individuare e quantificare le dimensioni del fenomeno: la discussione attorno a tematiche di omofobia e discriminazione di genere in Italia. Abbiamo compiuto una prima analisi sulle serie temporali fornite da Google Trends, in modo da comprendere l’interesse di ricerca degli Italiani per determinate parole nel motore di ricerca Google: omofobia, transfobia e LGBT. Abbiamo usato la libreria Pytrend per scaricare le serie temporali, visualizzarle ed elaborarle in Python. Per poter estrarre comprendere al meglio gli andamenti nel tempo delle ricerche abbiamo effettuato una decomposition delle time series per poter leggere in modo chiaro le sue componenti: in particolare mostriamo di seguito trend e stagionalità sia per omofobia che per LGBT. Si vede chiaramente come il trend di omofobia sia pressochè costante ad eccezione di un forte incremento dal 2019. Invece il termine LGBT, pur avendo meno picchi, risulta in costante crescita. Questo è sintomatico di un termine che –anche se con lentezza e fatica– sta entrando negli interessi e quindi nel vocabolario degli italiani.
Osservatorio per la sicurezza contro gli atti discriminatori Opera presso il dipartimento della Pubblica sicurezza, direzione centrale della Polizia criminale, per fornire un valido supporto alle persone vittime di reati a sfondo discriminatorio (hate crime o crimini d’odio), agevolare la presentazione di denunce e favorire l’emersione di quei reati.
La lettura del fenomeno discriminatorio è molto difficile per la poca rappresentatività del dato ufficiale. L’OSCAD ad oggi è l’istituzione che provvede alla raccolta e al monitoraggio delle segnalazioni di atti discriminatori in Italia su base razziale, religiosa, di genere e di orientamento sessuale. Secondo la dottoressa Francesca Capaldo, vice-questore della Polizia di Stato (OSCAD), le cause di questa mancanza di dati possono essere ricercate su vari fronti: le denunce e le segnalazioni di discriminazioni fanno ancora fatica ad emergere in maniera trasparente, per mancata fiducia nelle istituzioni, nelle forze di polizia, e per una serie di barriere sociali e legali: paura di ripercussioni sulla persona, imbarazzo, ricatto. Le conseguenze sono visibili –o meglio non visibili– come testimoniato dal fenomeno dell’under-reporting, e a partire da questa mancata attività di denuncia e segnalazioni ne consegue un’assenza di dati statistici che coprano e descrivano la manifestazione dei crimini, delle discriminazioni sulla base dell’orientamento sessuale e dell’identità di genere.
Tuttavia l’intensa attività di istituzioni come OSCAD nella sensibilizzazione pubblica, la formazione degli operatori di polizia e il lavoro con le associazioni LGBTQI+ sparse sul territorio nazionale, hanno favorito in parte un aumento delle segnalazioni negli ultimi 10. Questo non rappresenta il crescere dei reati e crimini a sfondo omofobico in senso assoluto ma piuttosto dimostra una maggiore sensibilizzazione sociale sul tema che sta alla base di un momento favorevole per l’apertura e l’ampliamento dei diritti civili. Il sistema di raccolta OSCAD, che ogni anno rilascia dati e report all’OSCE, è migliorato assumendo il titolo di fonte più attendibile per questo fenomeno in Italia, un’informazione rilevante per gli scopi di questa ricerca. Resta di fatto che il fenomeno discriminatorio è un fenomeno ampiamente sommerso: i valori reali mancano, e quelli forniti dalle associazioni e osservatori non hanno valenza statistica. Tuttavia, come testimoniato dal valore della sensibilizzazione e dall’esperienza di attivisti come Guaiana, la dimensione linguistica è determinante nell’essere lo specchio del fenomeno e la sua causa stessa. Ponendo attenzione al linguaggio riguardo omosessualità, transessualità e genere si possono evincere segnali, indicatori e spie sul fenomeno in generale.
" I dati sul fenomeno in Italia purtroppo mancano, tuttavia sempre più persone parlano."
Analizzando le serie temporali fornite da Google Trends sulle ricerche fatte dalə italianə su Google si evince un andamento lievemente crescente nel tempo delle ricerche riguardo “omofobia”. Quello che colpisce maggiormente è la forte stagionalità della ricerca del termine “omofobia” in corrispondenza delle settimane vicine alle ricorrenze LGBTQI+ quali Giornata Internazionale contro l’Omofobia, Bifobia e Transfobia(17 maggio) e Pride Month (Giugno). Queste ricorrenze creano dei picchi di interesse localizzati nel tempo, che secondo Guaiana –anche se fortemente limitati nell’estensione temporale– possono muovere la consapevolezza su certi temi in modo determinante. Diverse sono invece le curve di popolarità per le ricerche Google di “transfobia” e “LGBT”, che invece mostrano dei picchi minori durante le ricorrenze LGBTQI+ ma un trend di crescita più costante, segnale di una consapevolezza che inizia ad emergere nella cittadinanza italiana riguardo al concetto di “transizione” di genere e alla sigle internazionali che identificano la comunità LGBT.
Un ulteriore indicatore dell’aumento della discussione attorno a determinati temi lo si può vedere anche dalle modifiche della pagina Wikipedia Italia di “omofobia”(sia aggiunte che cancellazioni), accresciuta notevolmente negli ultimi 10 anni, in particolare in corrispondenza del dibattito sulle unioni civili nel 2015.
Su Wikipedia abbiamo voluto osservare le modifiche nel tempo apportate dagli utenti alla pagina italiana di “omofobia” . E stato costituito uno scraper con le librerie Wikipedia e BeautifulSoup in grado di estrarre informazioni dalla tabella di modifiche della pagine nel tempo ed inserirle in un dataframe con le seguenti features: id modifica, data, byte della pagina, autore. Con questi dati è stato poi creato uno scatter plot al fine di documentare le modifiche nel tempo e l’entità in byte di ogni singola modifica.
La disparità tra l’assenza di dati sul fenomeno e la crescente discussione su di esso ci ha incentivato a cercare di colmare questo gap informativo. Al fine di generare nuova conoscenza sulla tematica, abbiamo così investigato con un’analisi esplorativa riguardo le sorgenti dati che avrebbero potuto contenere discussioni sulle tematiche di sessualità e di genere, per poter costituire un bacino di dati strutturati prima di allora inedito. Per cogliere le diverse sfaccettature del linguaggio, come Pasolini aveva scelto una pletora di contesti da sondare, noi abbiamo adottato un medesimo approccio online. La nostra ricerca si è quindi orientata su tre livelli di discussione che vivono in tre contesti diversi: il piano della politica parlamentare, il piano degli organi d’informazione e il piano delle reti sociali.
Il fine del progetto è quello di studiare il linguaggio degli italiani relativo a violenza di genere e sessualità in Italia. Per fare ciò abbiamo investigato, parafrasando Pasolini, tre “piazze” principali di discussione: gli stenografici degli interventi parlamentari alla Camera dei Deputati nelle Legislature XVII e XVIII, quotidiani nazionali e locali e infine Instagram. Vista l’assenza di dati relativi alle tematiche affrontate, si è reso necessaria una preliminare generazione di opportuni dataset per svolgere le analisi che ci siamo prefissati. Per fare ciò abbiamo sfruttato le potenzialità delle librerie python Selenium, BeautifulSoup e Requests per effettuare il cosiddetto scraping delle pagine web HTML di interesse.
Ma cosa muove oggi il dibattito sull’omofobia in Italia? Tra i vari argomenti la discussione è da mesi impegnata nella stesura ed approvazione del Decreto di Legge Zan. Il ddl Zan, indica una serie di "misure di prevenzione e contrasto della discriminazione e della violenza per motivi fondati sul sesso, sul genere, sull’orientamento sessuale, sull’identità di genere e sulla disabilità". In particolare, l'articolo 2 del disegno di legge mira ad allargare due articoli del codice penale che puniscono reati di propaganda e istigazione a delinquere per motivi di discriminazione razziale, etnica e religiosa. Di fatto, quello che propone il ddl Zan è di aggiungere a queste discriminazioni quelle per motivi di sesso, genere e identità di genere, orientamento sessuale, e disabilità. Al contempo, il ddl punta ad ampliare le aggravanti della legge Mancino del 1993 legge Mancino che sanziona e condanna frasi, gesti, azioni e slogan aventi per scopo l’incitamento all'odio, aggiungendo alle categorie quelle sopracitate. In più il ddl Zan prevede che l’ente di ricerca ISTAT svolga un monitoraggio sui crimini d’odio e stili dei report periodici con dati aggiornati sulla tematica. Il ddl Zan comunque non è del tutto nuovo: è il risultato di vari tentativi legislativi che non hanno visto l’approvazione come quella proposta da Antonio Di Pietro nel 2008 o quella di Anna Paola Concia nel 2010. TuttavIa è la prima volta che la discussione su tali tematiche ottiene un impatto mediatico tale in Italia, come vedremo nel corso dell’articolo.
Come suggerito dal professor Dolcini, il ddl Zan costituisce una summa di varie proposte non approvate, e dunque rappresenta un oggetto di discussione complesso e divisivo sul tema dell’omostransfobia, non solo in Parlamento. D’altronde le fonti istituzionali e giuridiche risultano essere fondamentali per il cambiamento culturale e linguistico della società Italiana. A partire dall’analisi di Google Trends e delle proposte di legge risulta esserci una relazione fra l’interesse delle persone nelle tematiche di omofobia e le discussioni in Parlamento. Questo non permette di comprendere appieno lo sfondo culturale italiano ma il tentativo di far emergere le forze che animano il dibattito e l’interesse sociale risulta essere parzialmente appreso. La crescente sensibilizzazione politica per un fenomeno prima di oggi ignorato totalmente o parzialmente, ha favorito un maggiore interesse nelle persone proprio verso quelle tematiche discusse in Parlamento.
Per caratterizzare il linguaggio relativo alle tematiche di sessualità e genere, abbiamo studiato il modo in cui la classe dirigente italiana parla in occasione degli interventi parlamentari alla Camera dei Deputati. La discussione parlamentare risulta distribuita equamente tra il centrosinistra e il centrodestra, confermando che le tematiche relative al sesso e al genere suscitano un interesse trasversale e generalizzato nelle forze politiche.
L’analisi è iniziata con lo studio del linguaggio parlamentare con l’intento di selezionare gli interventi che in qualche modo facessero riferimento alle tematiche di violenza di genere e omofobia per poi allenare un multi-classificatore che individuasse il linguaggio di CDX, CSX e M5S. Lo studio è iniziato con l’individuazione di una sorgente dati di riferimento che è stata riconosciuta negli stenografici della Camera. Questa scelta è stata guidata sia per la natura del linguaggio politico (più informale) utilizzato durante le discussioni parlamentari alla Camera, sia per la modularità del sito che permetteva di avere una granularità atomica politico-intervento all’interno di ciascun documento.
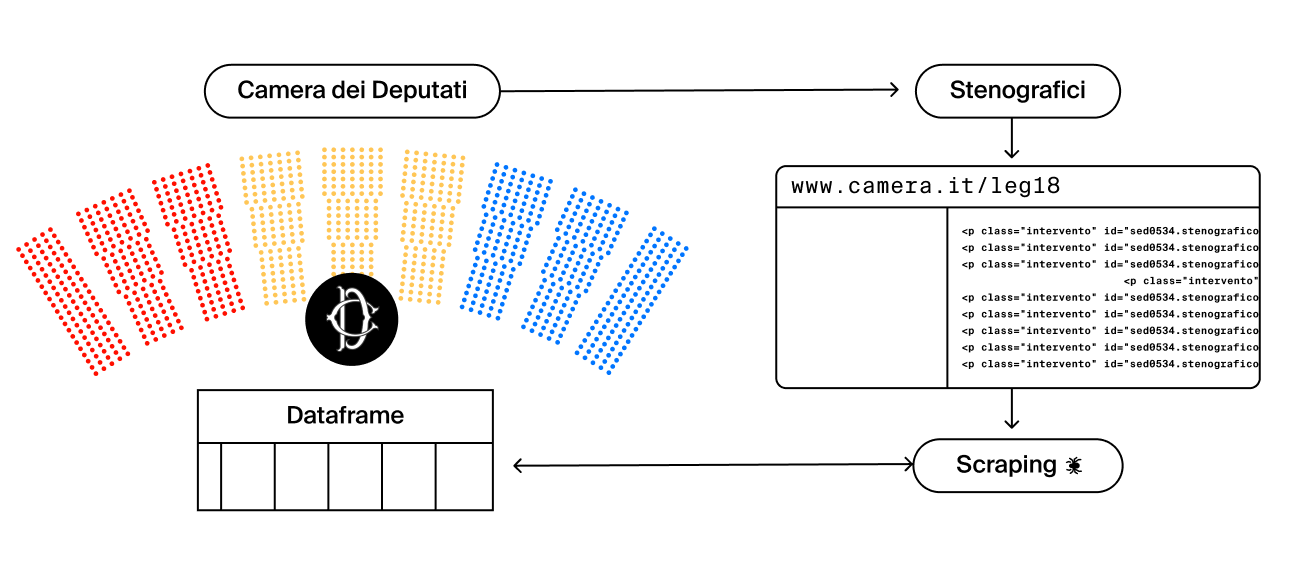
L’intervallo temporale di riferimento per lo studio è stato il range 2013-2021 (XVII-XVIII Legislatura) ed è stato scelto per un duplice motivo: il periodo in questione ha visto tre momenti maggiori di dibattito relativo alle tematiche omofobiche e di violenza di genere (proposta Scalfarotto, ddl Cirinnà, ddL Zan) e perché in tale intervallo temporale i partiti e i valori morali della classe dirigente protagonista della scena politica sono cambiati ma afferendo sempre alle medesime forze politiche (per esempio se ci fossimo estesi fino alla XVI legislatura avremmo dovuto studiare un panorama politico privo del M5S). Visto che la fluidità di creazione, scissione e cessazione della vita politica dei partiti in un intervallo di tempo abbastanza lungo è piuttosto accentuata in Italia (trasformismo), abbiamo deciso di svolgere le successive analisi considerando 3 poli politici (centrodestra-CDX, centrosinistra-CSX, MoVimento 5 Stelle-M5S) piuttosto che i singoli partiti.
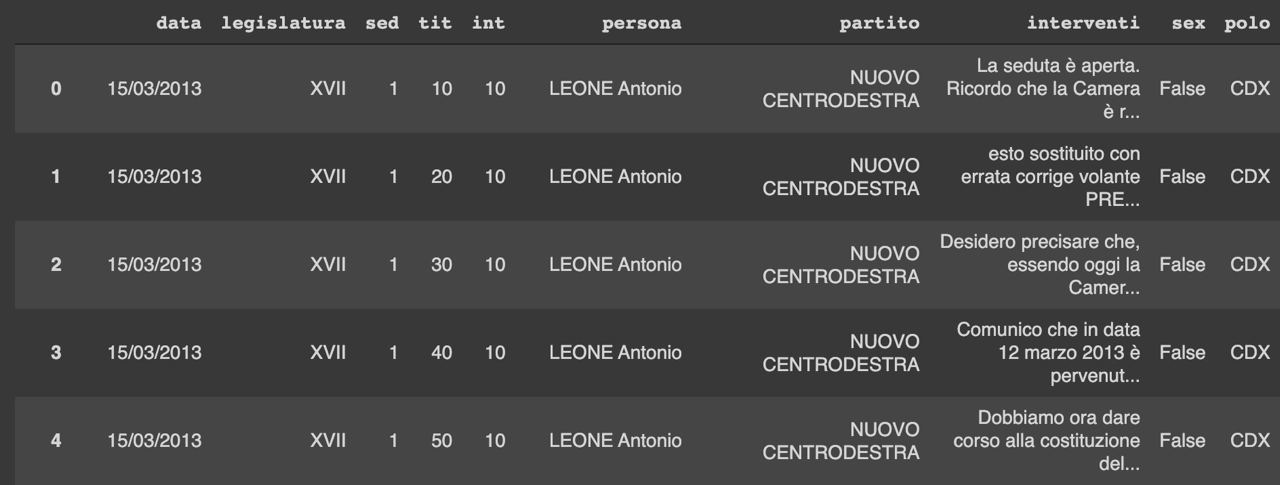
Sfruttando il Web Driver Selenium, il parser BeautifulSoup e la libreria Requests di Python, siamo riusciti a reperire le informazioni di cui avevamo bisogno e raccoglierle in un dataframe. Come si può osservare il dataframe ha una colonna per la data, la legislatura, una terna di numeri che identifica seduta e intervento, il politico che interviene, il partito e il testo dell’’intervento. Nel dataframe è presente anche una colonna di label binari ‘sex’ True/False e una colonna di tre etichette CSX, CDX, M5S la cui definizione è spiegata in dettaglio più avanti nel report.
Tuttavia l’importanza politica e l’interesse dei gruppi parlamentari rispetto a tali temi varia nel tempo. Attraverso uno streamgraph, che mostra con colori diversi la quantità di interventi alla Camera da parte dei tre poli, possiamo vedere come, durante le discussioni della scorsa legislatura, la sinistra sia intervenuta con maggiore insistenza attorno alle proposte di legge Scafarotto e Cirinnà, rispettivamente 2013 e 2016. Mentre per il ddl Zan si è visto un incremento della verbosità del centrodestra, in particolare nei giorni di discussione di Gennaio 2021.
Dato il dataframe con le sedute ci siamo posti il problema di come identificare gli interventi parlamentari alla Camera che in qualche modo trattassero le tematiche relative alla sessualità e alla violenza di genere (testi rilevanti). Per fare ciò abbiamo quindi ricercato nello storico della Camera le proposte di legge, presenti e passate, relative alle tematiche sessuali e di violenza di genere. Per avere la sicurezza delle scelte fatte abbiamo anche intervistato un autorevole giurista – Emilio Dolcini– il quale ci ha deliziato con un esaustivo e dettagliato excursus temporale sulle battaglie politiche e legislative riguardanti i diritti civili in Italia
Dato il dataframe con le sedute ci siamo posti il problema di come identificare gli interventi parlamentari alla Camera che in qualche modo trattassero le tematiche relative alla sessualità e alla violenza di genere (testi rilevanti). Per fare ciò abbiamo quindi ricercato nello storico della Camera le proposte di legge, presenti e passate, relative alle tematiche sessuali e di violenza di genere. Per avere la sicurezza delle scelte fatte abbiamo anche intervistato un autorevole giurista – Emilio Dolcini– il quale ci ha deliziato con un esaustivo e dettagliato excursus temporale sulle battaglie politiche e legislative riguardanti i diritti civili in Italia.
I promotori della discussione e del tentativo di rappresentare l’istanza all’interno del Parlamento si trovano nel centrosinistra. Inizialmente, un piccolo gruppo di politici afferenti all’area sinistra del parlamento iniziò sin dagli anni ‘90 a restituire dignità e onore al lavoro portato avanti dalle associazioni che da anni inviavano report degli episodi di omofobia all’attenzione del Parlamento. Col passare degli anni, la sinistra in generale ha quindi colto la necessità sociale –e talvolta cavalcato un trend favorevole– per portare determinate istanze sociali in parlamento sulla base dello scenario europeo ed internazionale che andava cambiando.
Invece la destra fino al 2010, come testimoniato dal giurista Dolcini presente in varie audizioni parlamentari, risultava spesso disinteressata, distratta o persino assente nelle discussioni. La crescente e più insistente presenza negli ultimi anni della destra nelle discussioni sull’omotransfobia in parlamento si può dunque motivare – sempre secondo Dolcini– con un rinnovato interesse nella difesa delle libertà di manifestazione del pensiero sulla sessualità e il genere. Ed è così che la destra ha spostato leggermente la narrazione, facendo sembrare gli omofobi le vittime di una possibile legge “liberticida”.
A seguito di questa prima selezione degli interventi (principalmente legati alla proposta di legge Scalfarotto, legge Cirinnà e ddl Zan), tuttavia ci siamo accorti, che il dataset ottenuto contava un numero limitato di interventi (circa 2000) cosparsi anche da rumore linguistico di fondo dovuto alla terminologia tecnica ricorrente in parlamento. Abbiamo deciso dunque di ampliare i testi rilevanti in due step:
1 – Provare una selezione ed un ampliamento tramite un’ulteriore ricerca per mezzo di Regex con il fine di filtrare gli interventi selezionati ed intercettare tramite parole chiave nuovi interventi per aumentare il corpora di testi rilevanti di base.
2 – Realizzazione di un classificatore binario allenato sui testi rilevanti di base (train set 85%, test set 15%) per riconoscere le discussioni a partire dal contenuto testuale. Il classificatore forniva True se l’intervento parlava di violenza di genere e omofobia e False per il contrario.
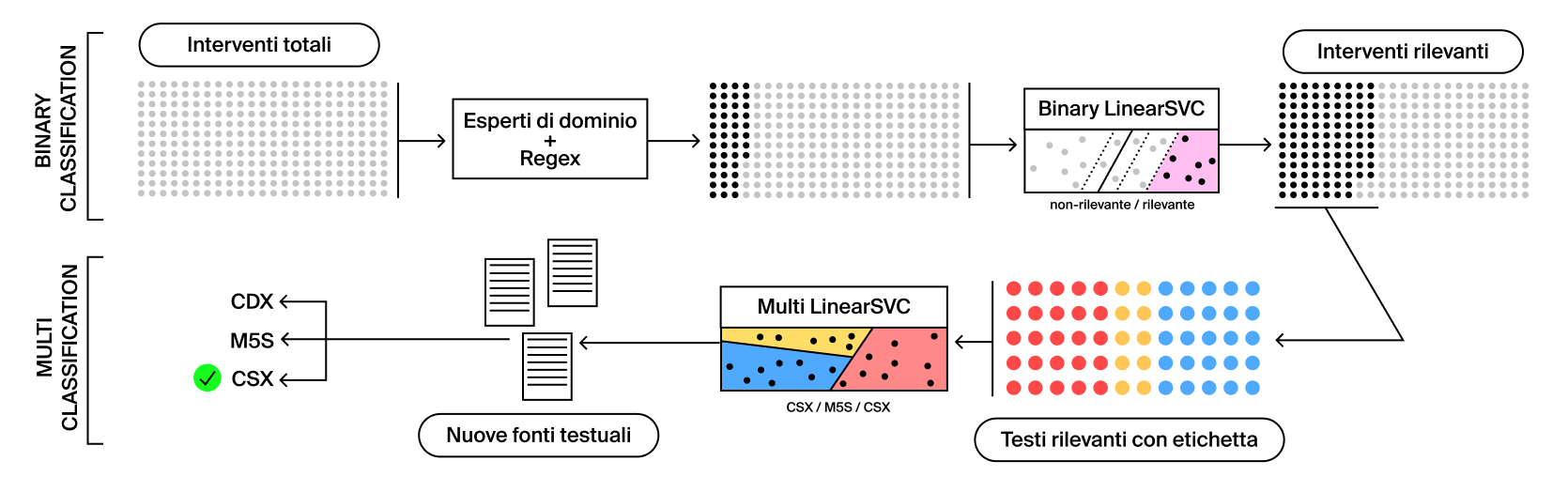
Visto la natura controversa degli argomenti affrontati, anche il linguaggio dei politici risulta essere variegato. Per esempio visualizzando spazialmente in due dimensioni la vicinanza semantica delle parole del vocabolario del centrodestra si osserva che alcuni termini notevoli come "gay", "lobby” e 'ideologia' si posizionano in forte prossimità sul grafico, manifestando quindi un utilizzo spesso concomitante di queste parole. Queste associazioni non risultano affatto sorprendenti a Guaiana, che rimarca come “lobby gay” sia un refrain che va avanti da anni, mentre “ideologia gay” sia un curioso neologismo proposto dalla destra recentemente. Anche la più stretta associazione della destra tra “sesso” e “gender” anzichè la versione italiana “genere” (maggiormente scelta dalla sinistra) risulta essere per l’attivista milanese un chiaro esempio di come l’esoticizzazione di concetti di facile comprensione sia una tecnica efficace di retorica politica. Anche la lettura del lessico del centrosinistra, porta delle interessanti osservazioni per Guaiana. La forte polarizzazione tra termini sentimentali e di violenza, per quanto riguarda le parole maggiormente associate a “sesso”, sono per l’attivista indicative di una semplificazione politically correct, che spesso la sinistra adotta trattando il tema. Sulla base dei testi selezionati alla Camera dei Deputati abbiamo inoltre creato un classificatore in grado di determinare l’orientamento politico di un testo (come centrodestra, centrosinistra o Movimento 5 Stelle) a seconda del linguaggio utilizzato. Lo scopo è stato quello di utilizzare questo tool per classificare il linguaggio dei quotidiani in base a quello che il classificatore ha imparato sul Parlamento. Il metodo ha il fine di aiutare l’analisi del fenomeno, ed in particolare di scoprire i punti di contatto tra testi diversi sulla base di un linguaggio comune.
Con questo modello, allenato sugli interventi selezionati a mano e tramite Regex, abbiamo classificato quindi anche i restanti interventi delle legislature XVII e XVIII. Su questa classificazione abbiamo anche posto una threshold di sicurezza per la selezione degli interventi True. In particolare abbiamo etichettato con True gli elementi che il classificatore individuava con True e che contemporaneamente si trovavano oltre una certa distanza dalla decision boundary individuata dal modello LinearSVC della libreria Sklearn, utilizzato per fare le predizioni. Questo valore di soglia è stato scelto come trade-off tra numero di interventi e sicurezza con il quale il classificatore faceva predizione.
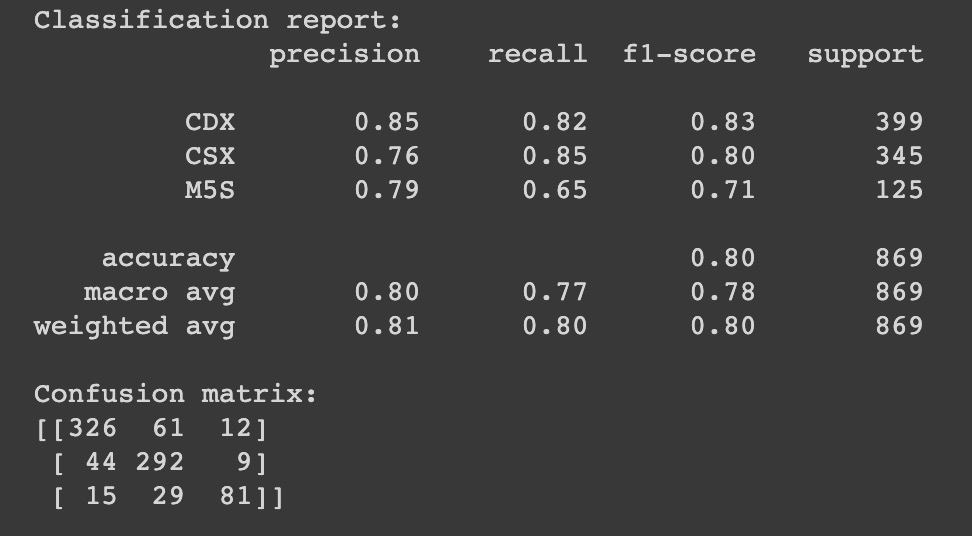
Il testo degli interventi parlamentari è stato tokenizzato sfruttando la classe CountVectorizer di Sklearn e implementando un analyzer customizzato basato sulle libreria SpaCy e NLTK per l’estrazione di lemmi e bigrammi. Il classificatore LinearSVC è stato calibrato su una configurazione di iperparametri subottimale tramite una grid search inizializzata con diversi valori di iperparametri. La performance finale del classificatore è mostrata di seguito.
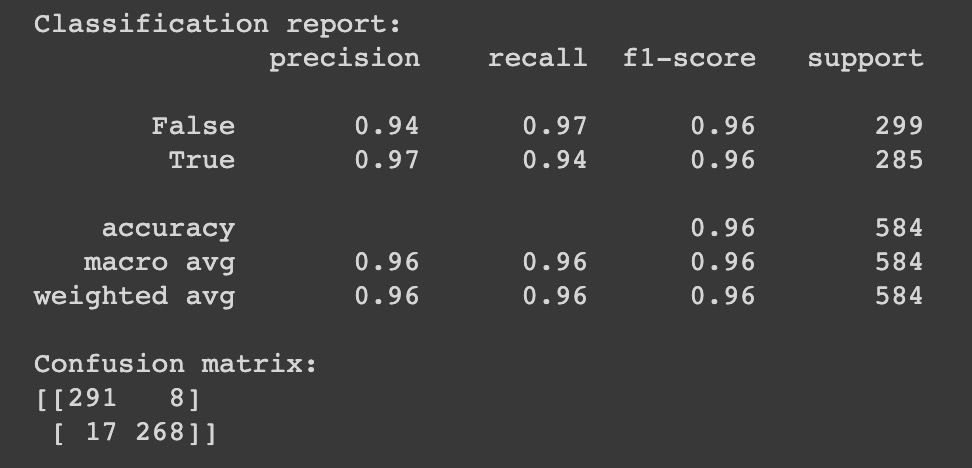
Le performance del modello risultavano essere piuttosto elevate e l’ulteriore scelta conservativa di selezionare come True solo gli interventi “più distanti” dalla decision boundary ha fatto sì che la precision del modello fosse auspicabilmente più alta. Con questa metodologia siamo riusciti ad ampliare il dataframe degli interventi riguardanti sesso e genere fino ad ottenere circa 5000 elementi. Nonostante lo studio fosse sviluppato attorno alla caratterizzazione dei poli politici, a titolo esplorativo e di indagine, abbiamo comunque realizzato, oltre alla distribuzione per polo, anche un grafico a barre che mostrasse la distribuzione degli interventi parlamentari, relativi a queste tematiche, anche per i partiti singoli.
Solo a questo punto, su questo dataset composto da solo interventi “sex=True”, abbiamo allenato (train set 80% e test set 20%) un modello multiclasse (CSX, CDX e M5S) per inferire come le varie aree politiche parlavano di queste tematiche.
Per il multiclassificatore abbiamo provato sia modelli basati su Decision Tree, Support Vector Machine (Linear SVC) che modelli ensemble (Random Forest). Dalla model selection è emerso che modello che meglio classificava era ancora una volta il LinearSVC di Sklearn. Le performance del modello finale, a seguito di Parameter tuning, sono mostrati in figura. Il modello aveva delle performance simili nel classificare il CDX e il CSX ma andava in maggiore difficoltà con il M5S a causa del minor numero di interventi su cui il modello poteva imparare.
Sulla base di questo modello, abbiamo speculato sul linguaggio utilizzato dalle fonti di informazione italiane. In particolare abbiamo fatto classificare gli articoli di 5 testate nazionali (Il Corriere della Sera, il Sole 24 Ore, la Republica, Avvenire, il Giornale) e delle testate del gruppo editoriale partecipativo CityNews dal modello allenato sul linguaggio del parlamento per cercare di scoprire se il sopracitato modello fosse in grado di riconoscere una linea editoriale particolarmente affiliata ad un certo linguaggio politico.
Sempre sugli interventi della Camera dei Deputati abbiamo compiuto un’analisi delle parole utilizzando la libreria di Word Embeddings di Gensim Word2Vec. Dopo aver diviso i nostri dati della Camera in 3 dataframe –uno per ogni polo– abbiamo allenato 3 modelli diversi di Word2Vec andando a mappare le parole degli interventi in uno spazio vettoriale denso, facendo emergere concetti e similarità semantica. Per creare i modelli è stato considerato una finestra di 10 parole all’interno del testo.
Dopo aver eseguito il calcolo di similarità semantica attraverso il metodo .similarity su alcune coppie di parole abbiamo deciso di visualizzare visivamente l’intero vocabolario di ogni partito in uno spazio bidimensionale. Questo è stato possibile attraverso la tecnica di dimensionality reduction t-SNE e la visualizzazione tramite scatter plot.
Gli organi di informazione sono l’anello di congiunzione tra la discussione che avviene nelle alte sfere della politica italiana, le vicende di politica locale, e le storie di cronaca che toccano il singolo cittadino. I giornali esercitando dunque una doppia pressione sia sulle discussioni di alto livello nelle camere parlamentari, sia sulle discussioni che tutti i giorni facciamo sui social.
La seconda sorgente di dati presa in considerazione è stata dunque quella riguardante alcuni organi d’informazione ufficiali –nella loro versione online. Cinque tra i quotidiani più letti a livello nazionale –Corriere della Sera, Il Giornale, Il Sole 24 Ore, Avvenire, la Repubblica – e il gruppo editoriale CityNews con 49 testate locali, ci hanno permesso di intercettare le istanze e l’interesse sulla tematica sia a livello nazionale sia in modo capillare sul territorio italiano.
Sui giornali nazionali abbiamo sondato gli articoli relativi alle query di ricerca “omofobia” e “DDL Zan” dal 2017 ad oggi. Le entità semanticamente trattate maggiormente cambiano in base al quotidiano di riferimento: per esempio, osservando il grafico sottostante si evince che il Sole 24 Ore è il quotidiano che dà meno spazio alle tematiche di violenza di genere e omofobia rispetto agli altri quotidiani. Oppure, è possibile vedere in modo chiaro nei numeri de Il Giornale e del Corriere della Sera che la persona sulla quale è posta maggiore attenzione è il cantante Fedez, per il netto schieramento a favore del ddl Zan.
La seconda piazza aveva lo scopo di palesare il linguaggio relativo a omofobia e identità di genere degli organi di informazione sia nazionali che locali.
Dal punto di vista degli organi di stampa nazionali abbiamo scelto le seguenti testate per avere un buon trade-off lettori/affiliazione politica:
Anche in questo caso si è reso necessario affidarsi alle potenzialità di Selenium, BeautifulSoup e Requests per realizzare dei dataframe inediti che permettessero di svolgere un’analisi del testo su tali sorgenti. In particolare per creare il dataframe abbiamo scelto di intercettare gli articoli riguardanti l’omofobia e il genere cercando e scaricando in modo automatizzato tutti gli articoli relativi alle query “Omofobia” e “ddl Zan” per ciascuna testata selezionata attraverso le barre di ricerca dei relativi siti. Alla fine del processo di scraping siamo riusciti ad ottenere un dataframe che avesse per colonne: la data, la testata giornalistica, l’url, il titolo, il testo dell’articolo e la query ricercata.
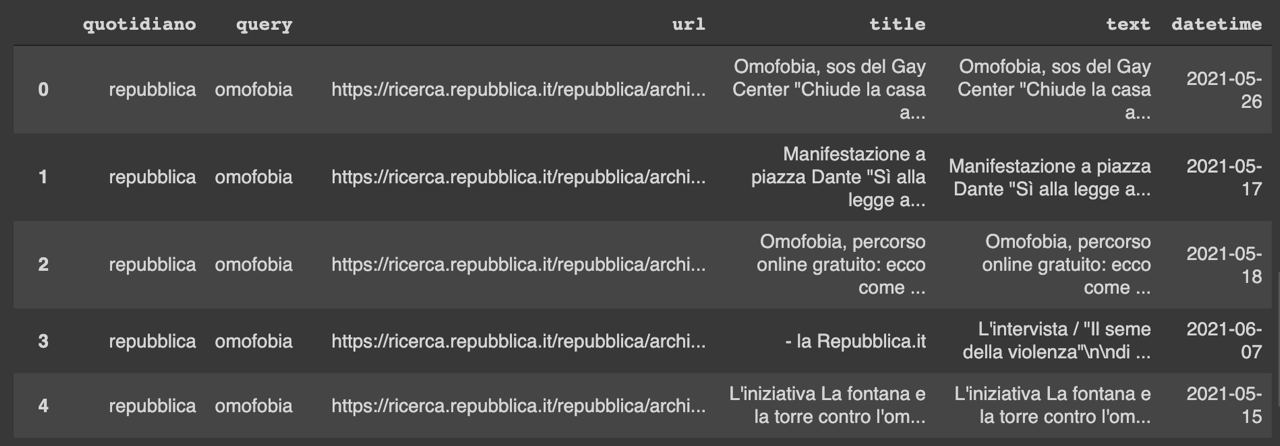
Successivamente a questo dataframe sono state aggiunte le seguenti colonne:
Come già accennato, con il multiclassificatore si sono anche classificati i relativi titoli degli articoli per vedere se il linguaggio utilizzato in un titolo in generale si rispecchiasse anche nel contenuto testuale. Nel diagramma Sankey di seguito si osserva che spesso non è così e che c’è una certa tendenza da parte dei testi di sinistra ad essere comunque associati a titoli con linguaggio di destra. Questo ci suggerisce che il linguaggio che il classificatore individua come di destra risulta essere più efficace da un punto di vista comunicativo.
Da questa analisi si individua anche che il linguaggio utilizzato dai giornali è principalemente di centrosinistra con l’unica eccezione per Il Giornale che risulta avere un leggero sbilanciamento verso articoli scritti con linguaggio di destra. Per quanto riguarda il linguaggio classificato come del M5S non si notano testate con numeri particolarmente alti di articoli così etichettati. Lo studio del linguaggio delle testate nazionali è continuato nella direzione di una caratterizzazione più fine degli articoli in base alla loro vicinanza di contenuto e semantica. Inizialmente abbiamo cercato di comprendere gli argomenti più trattati dalle varie testate estraendo le entità semantiche con TAGME e computando le più frequenti per ogni testata. Abbiamo poi generato la visualizzazione delle entità più discusse attraverso un bubble chart (uno per ogni testata) implementato in D3.
Per comprendere i particolari sotto-temi di discussione da parte dei giornali nazionali abbiamo provato ad estrarre raggruppamenti tematici attraverso Topic Modeling (algoritmo Latent Dirichlet Allocation), clustering su vettori Doc2Vec e clustering su vettori TF-IDF. La tecnica che ha offerto risultati migliori e meglio interpretabili è stata quella di clustering su vettori TF-IDF, che descriviamo di seguito. Per tale task abbiamo vettorizzato gli articoli di giornale con gli strumenti messi a disposizione dalle librerie Sklearn e SpaCy e successivamente abbiamo fatto un clustering con algoritmo K-Means. Nonostante il clustering K-Means sia un metodo di apprendimento non supervisionato prevede comunque l’inizializzazione di un parametro che corrisponde al numero di cluster che l’algoritmo deve trovare. Per scegliere un numero di cluster verosimile abbiamo utilizzato il “metodo del ginocchio” che prevede che la scelta ottimale del numero di cluster è quello corrispondente al valore per il quale l’ SSE (Sum of Squared Error) ha un ginocchio nel grafico SSE-numero di cluster. Nel nostro caso il ginocchio non era così palese ma sembrava essere attorno ad un valore k=8, come si evince dal grafico sottostante.
Un testo vettorizzato è rappresentabile con un vettore multidimensionale che quindi non è visualizzabile direttamente in uno spazio 2D. Per tale motivo abbiamo fatto uso dell’algoritmo t-SNE per la riduzione della dimensionalità che ci ha permesso di rappresentare i documenti all’interno dei relativi cluster in uno spazio 2D.
Per caratterizzare maggiormente il linguaggio dei giornali all’interno del tema ombrello di “omofobia” e “ddl Zan”, abbiamo anche cercato di individuare sotto-tematiche trattate negli ultimi anni attraverso la tecnica di clustering. Questo strumento ci permette di visualizzare il comportamento della sfera semantica del linguaggio nelle varie testate nazionali.
Dal grafico, per esempio, possiamo vedere che il giornale cattolico Avvenire con i suoi articoli pone particolare attenzione alle controversie relative al DDL Zan e all’aspetto liberticida del medesimo, sullo sfondo, come ben sappiamo, vi sono le dichiarazioni della Chiesa Cattolica sui comportamenti omosessuali, considerati contrari alla legge naturale. Mentre il Corriere della Sera lascia ampio spazio ad articoli relativi a cronaca di aggressioni, storie ed opinioni.
Possiamo sbilanciarci e ipotizzare anche una possibile relazione tra la politica italiana e la copertura mediatica. Sui maggiori quotidiani nazionali abbiamo dunque utilizzato il classificatore sviluppato sui testi della Camera, per comprendere l’orientamento politico del linguaggio usato negli articoli stessi. Oltre a veder confermato un linguaggio di destra o sinistra per quotidiani che storicamente hanno uno stampo schierato –come la Repubblica e Corriere verso centrosinistra e Il Giornale verso centrodestra– per curiosità abbiamo sfruttato il classificatore per scoprire se la connotazione politica dei titoli fosse la stessa riscontrata nei relativi articoli. Con l’avvento del giornalismo online infatti il modo di fare informazione e di scrivere titoli ed articoli è mutato.
Dalla visualizzazione seguente notiamo che l’orientamento politico individuato nei titoli non sempre rispecchia il contenuto dell’articolo a cui il titolo fa riferimento: possiamo vedere in particolare che metà degli articoli che hanno un linguaggio di centrosinistra sono veicolati da titoli di centrodestra. Questa preponderanza sembra indicare una maggiore efficacia del linguaggio di centrodestra nel diffondere messaggi in piccole porzioni di testo quali i titoli degli articoli online. Probabilmente, essendo portate avanti recentemente istanze da parte di schieramente politici di centrodestra, il linguaggio che è stato poi ripreso dai giornali nazionali, predilige il facile sapore politico piuttosto che accurate scelte socio-linguistiche. Le forze parlamentari hanno inserito con decisione l’elemento politico nella costruzione e sviluppo del linguaggio attorno alle tematiche di sessualità, ottenendo un connotato linguistico non più solo relativo alla società ma una espressione della politica e dei rapporti di forza. Questo linguaggio è stato poi evidentemente ripreso anche dai giornali, seguendo i topic di massima diffusione.


| Cluster Name | Common Words |
|---|---|
| Politica e DDL Zan | legge, diritti, genere, ddl zan, civili, presidente |
| Controversie DDL Zan e liberticidio | legge, genere, discriminazione, commissione, articolo |
| Manifestazioni e Pride | piazza, diritti, persone, città, manifestazione |
| Chiesa, Religione e Ideologia | chiesa, famiglia, ddl, vescovi, libertà |
| Giovani e aggressioni | ragazzi, legge, scuola, violenza, aggressione |
| Fedez e DDL Zan | primo, maggio, testo, orientamento, legge |
| Politica e Istituzioni | ddl, commissione, presidente, diritti, testo |
| Opinioni di VIP e storie | persone, mondo, donne, film, uomini, storia |
Tramite ispezione visiva dei titoli dei documenti ed estrazione di most common words, abbiamo dato un nome a ciascun cluster. Con una rappresentazione stacked barchart normalizzata abbiamo anche visualizzato come si distribuiscono gli articoli all’interno di ciascun cluster per ciascuna testata. Per esempio si nota che Avvenire pone maggiore attenzione sull’aspetto liberticida e controverso del ddl Zan. Come si può osservare dai bar chart della distribuzione dei cluster il più popolato è quello di “Opinioni, VIP e Storie” che mostra come i quotidiani nazionali diano ampio spazio alle testimonianze e alle vicende di personaggi famosi, tuttavia anche le tematiche relative alla scuola e alla politica trovano ampio spazio sui giornali a livello nazionale.
Attraverso l’analisi dei risultati di classificazione politica di Citynews emerge una generale polarità degli articoli verso sinistra con poche eccezioni come quella di Como, alla quale viene riconosciuta una linea editoriale maggiormente spostata verso centrodestra. Muovendosi da nord a sud nella penisola italiana, il classificatore non sembra riconoscere sensibili differenze editoriali sul territorio. Il gruppo editoriale Citynews probabilmente, essendo più legato agli episodi locali, e perciò più direttamente coinvolto con la gente, rende maggiormente giustizia al legame tra linguaggio e società rispetto alle testate nazionali, più vicine alla politica. Le persone e le loro storie sono forze dal basso che possono aiutare a superare quello che è il muro del linguaggio politico, e spostarsi sul linguaggio ‘vivo’, osservato e legato maggiormente alla realtà sociale.

La seconda fonte di informazione principale impiegata per intercettare il linguaggio utilizzato a livello territoriale è stata la redazione CityNews. Il gruppo CityNews comprende 49 testate giornalistiche diffuse sull’intero territorio italiano e risulta avere una copertura nazionale del 81%. Per queste sue caratteristiche di capillarità territoriale e copertura abbiamo scelto proprio questo gruppo per effettuare l’analisi testuale attraverso la penisola.
Come per i giornali nazionali anche in questo caso si è resa necessaria l’implementazione di opportuni scraper che inferissero il contenuto testuale dell’articolo direttamente dalla pagina web del sito. Il fatto di avere 49 testate fagocitate dallo stesso gruppo editoriale ha fatto sì che le strutture delle pagine web delle testate locali fossero caratterizzate da un format standard (a meno di correzioni minori). In questo caso si è scelto di scaricare tutti gli articoli relativi alla sola query “omofobia” perché la discussione attorno al ddl Zan ha una dimensione meno locale e più di politica nazionale. Al termine della procedura abbiamo ottenuto un dataframe che aveva per colonne: la data, la città della testata, il tipo di notizia (cronaca, video ecc.), il link dell’articolo, il titolo dell’articolo, il testo dell’articolo e la zona geografica di riferimento della città della testata (nord, centro, sud).
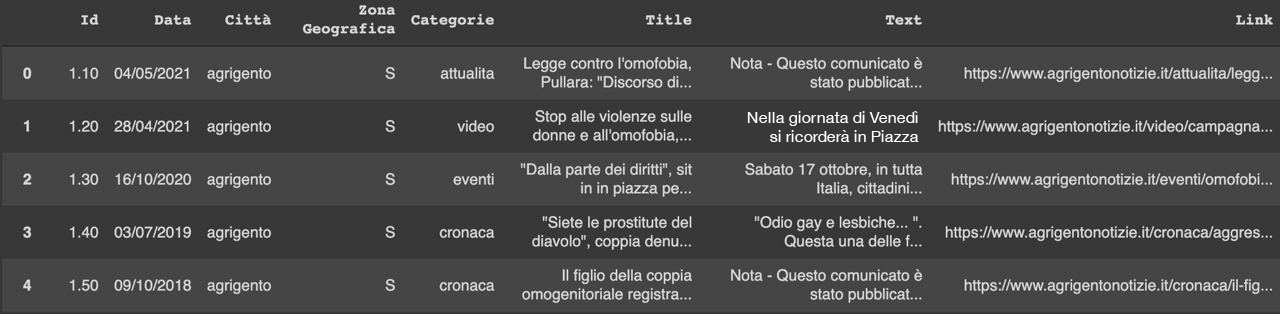
Per le testate locali si è scelto di focalizzare parte dello studio del linguaggio solo sulla cronaca, dimensione che a livello nazionale è intrinsecamente meno presente. Con lo strumento TAGME, che riconosce e identifica sequenze di parole semanticamente significative e le collega alle pagine di Wikipedia pertinenti, abbiamo estratto le principali e più frequenti entità che comparivano nelle notizie di cronaca in 10 testate locali scelte in base al numero di articoli prodotti e in modo da avere una rappresentanza generale dell’intero territorio italiano. Le entità ottenute presentano di base i macro-concetti legati alla tematica generale (transessualità, transfobia ) però presentano anche alcune locuzioni specifiche del territorio della testata analizzata (per Pisa, per esempio compare Ponte di Mezzo). Abbiamo effettuato clustering anche sui giornali locali di CityNews, adottando un approccio simile a quello dei quotidiani nazionali, descritto sopra. Per effettuare la tokenizzazione dei testi abbiamo utilizzato le potenzialità della libreria SpaCy utilizzando un filtro piuttosto selettivo sulle parole da utilizzare basato su Part of Speech tagging per selezionare solamente i nomi e gli aggettivi che comparivano nel testo e per ridurre il rumore lessicale nei token estratti. Con i testi vettorizzati, abbiamo effettuato un clustering di tipo K-Means su tutti gli articoli CityNews scaricati individuando come 8 il numero di cluster ottimale (“metodo del ginocchio”). Tramite ispezione visiva e realizzazione di liste most common words realizzate per ciascun cluster, abbiamo rinominato tali raggruppamenti con un label rappresentativo.
| Cluster Name | Common Words |
|---|---|
| Eventi e iniziative giovanili | associazione, manifestazione, giovani, scuole |
| Eventi e spettacolo | sabato, spettacolo, domenica, musica, pubblico |
| Film “Un Bacio” | Bacio, ragazzi, felicità, protagonisti |
| Istituzioni e politica | legge, diritti, persone, comunale, presidente |
| Ricorrenze e Manifestazioni | maggio, giornata, discriminazioni, associazioni |
| Sentinelle in Piedi | Piazza, piedi, sentinelle, manifestazione, legge |
| Video e Multimedia | definizione, animata, video, manifestazione |
| Violenza e Aggressioni | aggressione, episodio, violenza, ragazzi |
Abbiamo anche realizzato una barchart per la visualizzazione della distribuzione degli articoli di giornale all’interno dei cluster per città di riferimento . Dall’analisi non si osservano degli sbilanciamenti significativi dipendenti dalla città analizzata, tuttavia si riscontra una generale diffusione di articoli relativi ad eventi e manifestazioni come segnale di una consapevolezza e sensibilizzazione sempre più diffusa in reazione alle tematiche di identità di genere e lotta alla violenza. Infine anche per i giornali locali abbiamo classificato con il modello allenato sulla Camera dei Deputati, gli articoli relativi alle varie città e visualizzato le distribuzioni su una mappa interattiva. La linea editoriale, secondo il classificatore, ha un linguaggio principalmente di sinistra con un’unica eccezione per Como che presenta una maggioranza di articoli scritti con linguaggio di destra. In avanzamento successivo della ricerca potrebbe essere interessante provare a incrementare le performance del multiclassificatore per osservare se con un classificatore più fine si riscontrano differenze.










Per comprendere più approfonditamente gli argomenti discussi sulla cronaca è interessante ispezionare entità semantiche più comuni che compaiono negli articoli di cronaca relativi a 10 città selezionate, tra sud, centro e nord Italia. Queste entità ci danno una vivida idea dei concetti e temi di carattere sia generale, che specifico, discussi nella cronaca cittadina di alcuni dei capoluoghi di provincia italiani, spesso evidenziando anche filoni di news prolungati nel tempo. Vediamo per esempio che spesso a Bologna le vicende di omofobia si aprono su scenari di bullismo o persino fascismo, oppure a Firenze e Perugia si menzionano spesso associazioni LGBT di rilievo come Omphalos oppure La Manif pour Tous, o ancora a Roma dove la cronaca omofoba si interseca con narrazioni razziste e antisemite. Il fatto che atti omofobici siano spesso presenti assieme ad altri atti discriminatori (ad esempio su base razzista) suggerisce due aspetti. Il primo, che i fenomeni legati a crimini d’odio e alla discriminazione abbiano una natura sfaccettata che deve essere considerata nella sua complessità. Ed il secondo, che una più precisa articolazione terminologica sulle tematiche discriminatorie potrebbe portare al superamento di ambiguità linguistiche fin troppo spesso utilizzate dai giornalisti.
L’ultima “piazza” online analizzata è Instagram. Essendo uno dei social in più rapida crescita in Italia, lo abbiamo considerato il medium adatto per investigare la vox populi. La raccolta di dati su instagram –avvenuta tramite ricerca dei post corrispondenti agli hashtag “#omofobia” e “#ddlzan”– ha coperto l’arco temporale dall’inizio del 2020 ad oggi. Analizzando le caption dei post è stato possibile ricavare interessanti insight sulla popolarità di parole, hashtag ed emoji che vanno a caratterizzare il linguaggio veloce e dinamico del social media.
L’ultima piazza analizzata è quella più di “basso livello” cioè quella che intercetta il linguaggio delle persone comuni sui social network. Abbiamo scelto di analizzare Instagram sia per la possibilità di fornire dati sia testuali che grafici (immagini) che per la sempre maggiore diffusione di questo social in una fascia più o meno giovane della popolazione nonché la predisposizione del social alla promozione di battaglie e campagne di sensibilizzazione sui temi legati ai diritti civili. Lo stesso esperto di dominio Yuri Guaiana ci ha riferito che Instagram è sempre più utilizzato dalle associazioni per catalizzare tali campagne.
Alcune parole a partire dall’hashtag ‘omofobia’ nel tempo risultano comportarsi come prevedevamo ma con dei risvolti interessanti. Sulla linea temporale infatti ci sorprende osservare come alcuni termini siano costanti ed altri abbiano visto incrementi repentini negli ultimi tempi. La parola lgbt, nonostante sia ovvio che co-occorra assieme ad omofobia, può suggerisce una maggiore familiarità delle persone nell’utilizzo di questa parola, forse con l’intento profondo di unire la discriminazione ‘omofobia’ e la categoria di persone che viene discriminata: ‘lgbt’. Un richiamo forte da parte della vox populi che dichiara a suon di hashtag –sulla linea del tempo costante con alcuni picchi– l’esistenza di questo fenomeno e delle persone che lo subiscono tutti i giorni.
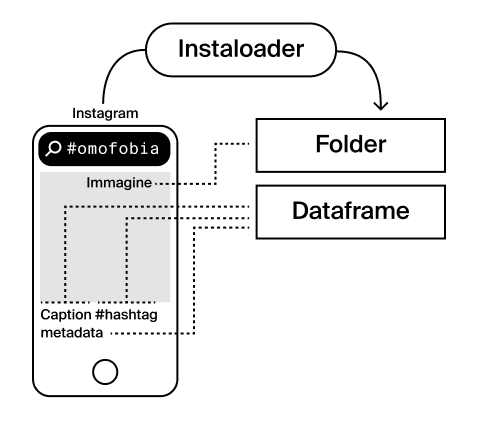
Anche per questa fonte, non essendo già presenti dei dati direttamente utilizzabili, abbiamo creato un dataframe sfruttando le potenzialità della libreria Instaloader che permetteva di effettuare ricerche definendo la finestra temporale d’interesse e i post relativi a un determinato hashtag. Per mantenere la consistenza con le analisi delle precedenti fonti esaminate, abbiamo cercato i post relativi agli hashtag #omofobia e #ddlzan in un intervallo temporale che va da gennaio 2020 a aprile 2021 per #omofobia e da luglio 2020 a aprile 2021 per #ddlzan. Il dataframe ottenuto con la libreria, ripulendo il testo con opportune Regex ed estraendo emoji e hashtag dalle caption è quello di seguito.Il dataframe si predispone particolarmente a fare analisi delle caption, most common hashtag e most common emoji.
Sulle caption corrispondenti all’hashtag #omofobia abbiamo anche effettuato un’analisi più profonda esaminando la vicinanza semantica tra termini. Partendo dalla ricerca di alcune parole consigliateci da esperti di dominio abbiamo rilevato interessanti associazioni che caratterizzano il linguaggio degli italiani su Instagram oggi. Attraverso quest’analisi è stato possibile constatare come il termine denigratorio “frocio”, così come i suoi vicini “ricchione” e “checca”, siano frequentemente associati a termini che connotano l’aspetto esteriore come “smalto” e antichi tormentoni come “travestito”. Come rimarcato da Guaiana, questo strumento rende possibile la validazione di fenomeni linguistici troppo spesso considerati solo nella loro dimensione “percepita”.

Successivamente abbiamo utilizzato il modello di Gensim Word2Vec per individuare parole semanticamente simili a parole chiave della discussione definite da utente. Per questa analisi abbiamo deciso di non rimuovere gli hashtag dalle caption perchè la loro presenza è stata da noi ritenuta importante per catturare ulteriore semantica e per individuare anche gli hashtag vicini. I risultati ottenuti con il W2V sono interessanti. Come si può notare per dalla tabella delle word similarity a partire da 3 queries, il linguaggio risulta molto variegato e vivo. Diversamente dall’analisi del testo del parlamento, su Instagram il linguaggio è molto più informale con termini dispregiativi o negativi forti.
| Frocio | Omofobia | Ddlzan |
|---|---|---|
| Ricchione | Omotransfobia | Ddlzansubito |
| Checca | Iorestoacasa | Diamociunamano |
| Traverstito | Stophate | Monicacirinna |
| Urlando | Giornatamondiale | Stopabilismo |
| Smalto | Dirittiumani | Vanityfairitalia |
| Spinte | Dirittilgbt | Giovanidemocratici |

Inoltre, strumenti di questo tipo rendono accessibile anche l’individuazione e la valutazione di strategie di comunicazione di massa, portate avanti sempre di più attraverso questi canali. I social permettono infatti a tutti di cogliere il fenomeno del momento che sta ‘sulla bocca di tutti’ e allo stesso tempo di cavalcarlo per veicolare un messaggio. E’ il caso della campagna tramite l’hashtag ‘diamociunamano’ portato avanti da VanityFair Italia che ha subito generato una successione di ri-condivisioni del suddetto da parte di VIP e non solo. Il caso di Vanity Fair è emerso a partire dai termine semanticamente vicini a ‘ddl zan’. Citando McLuhan, sociologo e filosofo, è chiaro come gli effetti dei prodotti della comunicazione siano visibili sia sulla società, sia sui comportamenti dei singoli.
Lo studio di instagram si è completato con la realizzazione di un grafo di co-occorrenza degli hashtag dei post relativi al hashtag #omofobia. Per l’esattezza abbiamo realizzato un file .ncol nel quale abbiamo riportato i nodi e i pesi: per nodi abbiamo considerato gli hashtag che co-occorrevano all’interno di uno stesso post e come pesi il numero di co-occorrenze delle varie coppie di hashtag. Abbiamo considerato inoltre il grafo come non orientato e abbiamo rimosso l'hashtag query #omofobia per evitare di ridurci allo scenario di full-mesh. Per visualizzare in modo non eccessivamente caotico il grafo, abbiamo semplificato il grafo attraverso metodi backboning offerti dalla omonima libreria con la quale abbiamo eliminato rumore e archi con pesi trascurabili ed i nodi con basso grado. Attraverso gli strumenti offerti da R, abbiamo poi individuato 4 community principali (con più di 100 nodi ciascuna), riportate di seguito:
Il grafo, epurato dalla parte più rumorosa, dagli archi con peso minore e dai nodi con grado minore è stato poi processato attraverso il software Gephi per la visualizzazione grafica. La rete, visualizzata in questa veste, funge anche da ottimo tool per l’ispezione visiva da parte dell’utente, in particolare per comprendere l’efficacia di un eventuale campagna comunicativa social o per studiare le connessioni per generarne una.

Visto il tempo limitato, non siamo riusciti ad effettuare un’analisi delle immagini associate ai post di instagram nonostante il dato .jpeg fosse a nostra disposizione. Analisi future possono essere orientate verso un object detection per individuare elementi visivi ricorrenti e per fare un confronto con i concetti frequenti presenti nel linguaggio utilizzato su IG e sui quotidiani.
Contesto: Durante questi mesi di studio legato al linguaggio relativo all’identità di genere e alle violenze ad esso legate, abbiamo scoperto che il fenomeno è meno semplice di quello che possa sembrare. In particolare, la presenza di canoni sociali dipendenti dal periodo storico analizzato, l’assenza o presenza di leggi nell’ordinamento giuridico e una diffusione del fenomeno molto dipendente da fattori soggettivi e legati al contesto sociale, fa sì che che non esista ancora una metodologia data driven riconosciuta in modo universale per analizzare con occhio critico e con metriche il più oggettivo possibile fenomeni come quelli relativi alla violenza di genere.
Da un confronto con Emilio Dolcini (giurista) e Yuri Guaiana (attivista), è emerso che c’è molta confusione nel panorama sia legislativo sia associativo e che i dati sono spesso fonte di strumentalizzazioni e soggettivizzazione per perseguire i propri interessi comunicativi. Da questi elementi, risulta chiaro che la realizzazione di un osservatorio che unisca metodi tradizionali di indagine (testimonianze, segnalazioni, ecc) e metodi di machine learning e data mining per rendere meno soggettive le analisi, sia molto richiesto e urgente.
Mission: Un osservatorio che sfrutta tecniche analitiche di analisi e che reperisca dati, non solo da fonti ufficiali, ma anche dai dati che gli utenti rilasciano in modo indiretto sul web, avrebbe un duplice vantaggio: mappare con una metodologia scalabile e analitica fenomeni sociali anche complessi prevedere e anticipare il realizzarsi di violenze tramite lo studio dei dati
L’assenza di dati ufficiali statisticamente attendibili non ci hanno permesso di validare se l’analisi del fenomeno da noi condotta sia rappresentativa della realtà delle cose. Tuttavia, Yuri Guaiana ci suggerisce che che strumenti e metodologie analitiche come questa –unite a conoscenza qualitativa in materia LGBT e in campo politico– possano costituire le basi per lo sviluppo di una discussione sana e meno divisiva. L’attivista rimarca come anche l’interpretazione politica di certi risultati analitici non debba spaventare, ma possa gettare le basi per una discussione che – “partendo dal dato e non dalla sola ideologia”– possa essere meno speculativa. A partire dalla mancanza di dati possiamo quindi trovare le motivazioni per l’incontro di persone con diverse competenze e prospettive al fine di trovare strumenti e metodologie nuove per catturare il fenomeno. La facilitazione di un dialogo su una tematica delicata e divisiva come questa può trovare –sempre secondo Guaiana– ampio spazio nell’alveo universitario. Proprio l’interdisciplinarietà può essere la nuova frontiera per lo sviluppo di un dialogo sempre più aperto sulla sessualità e sul genere. L’incontro tra discipline contribuirebbe all’emersione di nuove domande, definizioni e letture del fenomeno.